Support Vector Machines
(a) Overview
Support Vector Machines are supervised learning models used for classification and regression. SVMs aim to find the optimal hyperplane that best separates data points of different classes in a feature space. SVMs are considered linear separators because they aim to find the optimal hyperplane that separates data points of different classes using a linear decision boundary. SVMs use the kernel trick to project data into a higher-dimensional space where a linear separator might exist. In the dual form of the SVM optimization problem, the classifier makes predictions using only dot products between data points. Instead of working directly with the original input features, it evaluates how similar a new data point is to each of the training points by measuring their geometric alignment. This similarity is calculated using a function called a kernel, which effectively replaces the traditional dot product. The kernel allows the SVM to operate in a higher-dimensional space without explicitly transforming the data into that space.
The polynomial kernel maps the input features into a higher-dimensional space using polynomial combinations of features.
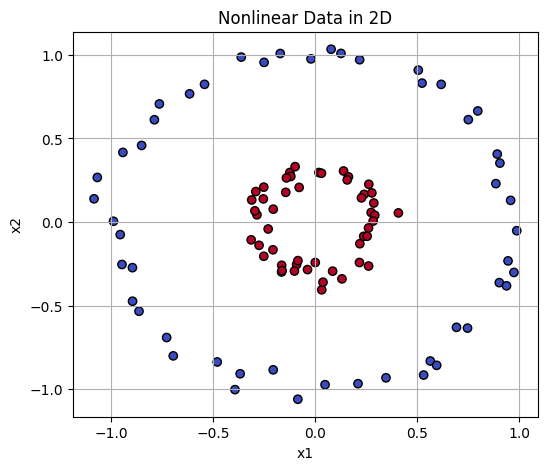
Radial Basis Function Kernel measures the distance between two points and returns a value close to 1 if they are similar or close together and 0 if they are different or far apart.
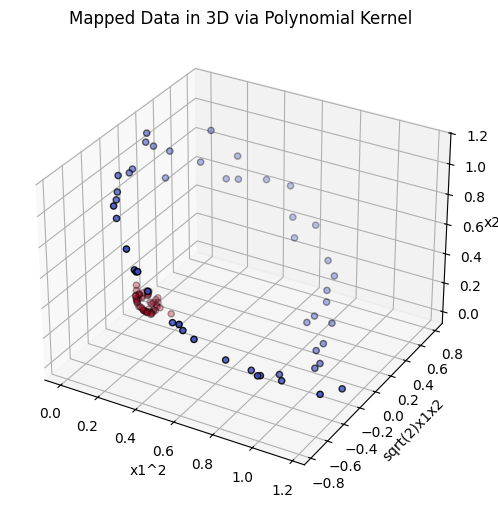
(b) Data Preparation
The dataset used is from the Low Value Care FY23 Public Data report. It includes information on service type, region, payer type, and associated spending. Each row represents a healthcare service entry for a given payer and year. The goal is to classify whether the low-value care spending is above the median threshold, making this a binary classification task.
The Training and test data must be disjointed because in supervised learning, model performance is evaluated on unseen data. If the same data points appear in both the training and testing sets, the model could memorize patterns and overfitting will occur, giving an inflated sense of accuracy. Ensuring the sets are disjoint preserves the integrity of the evaluation. To evaluate the model’s performance, the dataset was split into two parts, the Training Set (80%), used to train the SVM model, and the Testing Set (20%), used to evaluate the model’s performance on unseen data. This was done using sklearn.model_selection.train_test_split().
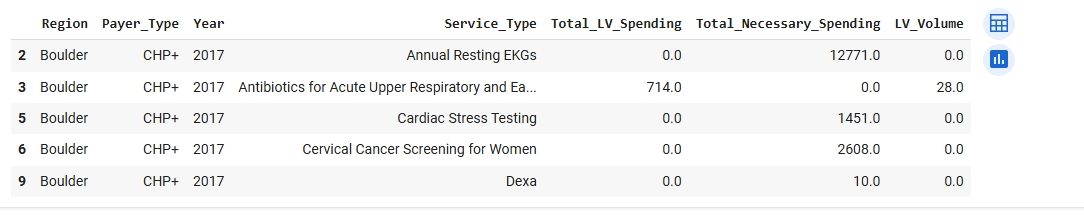
Data Preparation and Train-Test Split for SVM: The dataset was first cleaned to include only numeric and labeled records with valid values for low-value care spending and service volume. A new binary target variable, High_LV_Spend, was created to indicate whether a record’s total low-value spending exceeded the dataset’s median value. This transformation allowed the classification task to be framed as a supervised binary classification problem.
To evaluate model performance fairly, the data was divided into training and testing sets, ensuring they were completely disjoint. This separation is essential in supervised learning as the training set is used to build the model, while the testing set measures its ability to generalize to new, unseen data. Allowing overlap between the sets would lead to data leakage, artificially high accuracy, and unreliable evaluation metrics.
Support Vector Machines (SVMs) require input data to be both numerical and labeled, as they rely on geometric operations such as dot products to compute distances and margins between data points. These calculations cannot be performed on raw categorical or unlabeled data. Additionally, because SVMs are supervised models, they must be trained using examples with known class labels in order to learn an effective decision boundary.
Test Dataset Sample
A sample of the testing data used to evaluate the SVM model can be downloaded below:
Training Dataset Sample
A sample of the training data used to build the SVM model can be downloaded below:
(c) Code
View the full SVM Code Notebook
(d) Results
The Support Vector Machine classifier achieved an accuracy of approximately 73%, correctly predicting 1,095 out of 1,504 test cases. This represents a strong baseline, particularly given the relatively balanced distribution between high and low-spending classes.
For Class 0 (Low Low-Value Spending), the model demonstrated high recall, meaning it successfully identified most low-spending cases. However, it showed a modest rate of false positives, labeling some actual low spenders as high spenders. In contrast, Class 1 (High Low-Value Spending) was predicted with slightly higher precision, though the model missed a number of high-spending cases, reflected in a lower recall for this class.
The confusion matrix highlights this balance. The model correctly identified 568 low-spending cases (true negatives) and 527 high-spending cases (true positives). However, it also generated 178 false positives (low spenders misclassified as high) and 231 false negatives (high spenders misclassified as low).
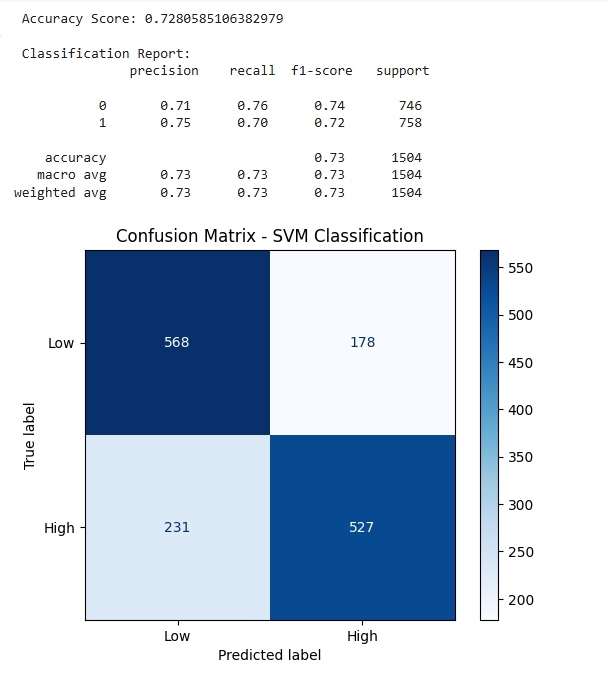
The macro and weighted averages of precision, recall, and F1 score indicate a generally balanced performance across both classes. This suggests the model is not overly biased toward either outcome, which is ideal in balanced classification tasks. However, the relatively higher number of false negatives for high spenders suggests a potential area for model improvement. If minimizing missed high-spending cases is critical for policy or operational reasons, future iterations of the model could incorporate adjusted class weights, hyperparameter tuning, or alternative kernel functions to optimize performance further.
(d) Results: The radial basis function (RBF) kernel with C = 10 delivered the strongest overall performance, achieving an accuracy of 79.1%. It outperformed both the linear and polynomial kernels, indicating that the decision boundary in this classification task is likely nonlinear. While the linear kernel (C = 10) was simpler and still relatively effective, it misclassified a larger portion of high-spending examples. The polynomial kernel performed the weakest overall in this configuration, suggesting that it may not be well-suited to the patterns present in this dataset. This SVM analysis demonstrates that the RBF kernel was best at capturing the complex relationships between features, achieving a classification accuracy of nearly 79%. These findings suggest that low-value care spending patterns are not linearly separable, and more flexible models like RBF are required to accurately classify them.
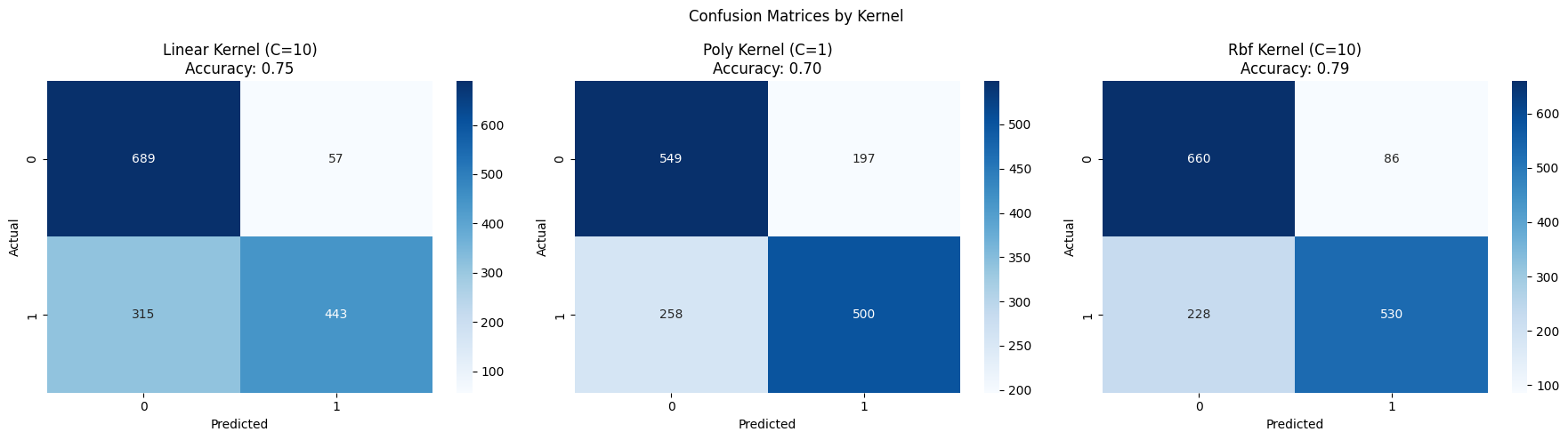
SVM Kernel Performance Summary
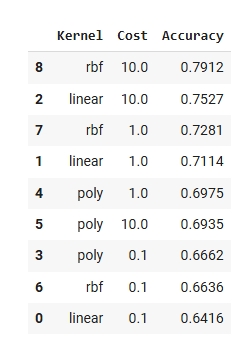
The table below shows the accuracy achieved by each kernel type across different regularization (C) values.
(e) Conclusions
This analysis used Support Vector Machines (SVMs) to classify whether low-value healthcare spending exceeded the median, based on structured features such as region, payer type, service type, necessary care spending, and service volume. Three kernel types linear, polynomial, and radial basis function were evaluated across multiple regularization (C) values. The RBF kernel with C = 10 achieved the highest accuracy at 79.1%, indicating that the relationship between input features and spending classification is likely nonlinear and benefits from flexible, high-dimensional decision boundaries.
While the linear kernel offered computational simplicity, it underperformed in identifying high-spending cases. The polynomial kernel showed the weakest performance overall, likely due to its sensitivity to parameter tuning and increased model complexity. These results suggest that SVMs with nonlinear kernels like RBF are well suited for modeling healthcare cost data, where patterns often defy linear separability.
The classification model effectively identified payer-region combinations likely to exceed median low-value care spending, offering potential applications in targeted audits, quality improvement efforts, and health system policy design. Future work could expand the feature set to include provider characteristics or demographic variables, implement cross-validation for improved generalizability, and compare SVM performance to alternative classifiers such as decision trees or ensemble models.